資料庫 (Database) 對資料工程師 (DE)、資料分析師 (DA)、後端工程師 (BE) 而言,算是共同的資訊承載體,無論資料如何在資料管線 (data pipeline) 或應用程式 (application) 中流轉,大多數的商業邏輯,最終仍會在資料庫的資料紀錄 (records) 被展現出來。
今天我們就用一個新創團隊的發展階段,來瞭解資料庫正規化與反正規化的用意,和各個職能角色又是什麼關係?
假設今天我們要籌組一個新創團隊,致力於提供一站式網購服務,讓任何註冊這個網站的會員都能夠任意地在網站上找得到的店家下單購物。
在這個網購服務背後的資料庫系統,最被看重的特性就會是效能。在這樣的前提下,後端工程師對資料庫設計的兩大目標為:
降低資料重複性:盡可能地避免相同的資訊被存在不同的表中,可確保儲存空間的精簡化。
避免資料不一致:由於資料沒有冗餘性 (reduenancy),查找與寫入更新時出現不一致 (inconsistency) 的風險就降低了。
讓我們來看看下面這份資料。這是網購服務背後的交易紀錄,很像我們平常用表格紀錄資訊的方式,讀起來很易懂。
這個樣式雖然直覺,但要更新特定資料時,是不是不太效率呢?例如,假設『果汁』這個商品正確的名稱是『檸檬汁』,我們要更新資料時,要一筆一筆地挑出 purchase_detail 有果汁字樣的紀錄,就非常地麻煩了。更別提資料量大時,可能是個嚴重的效能瓶頸。
於是,我們開始遵循資料庫設計原理之一:正規化 (normalization)。
【原則】
每一列資料的欄位值都只能是單一值,不要在同一欄位塞多個值。
不用多個欄位表達同一個事情。
資料表中需有 primary key (pk) 唯一值,且其他欄位都相依於 pk。
沒有任何兩筆以上的資料完全重複。
【解法】
確認是否有重複表達同一意涵的欄位。
假如一個人一次的購買紀錄裡可能有多個商品,不建議用 product_1, product_2 … 多個欄位紀錄,而是用多筆資料來儲存。
將欄位內重複的資料分別存為不同筆資料。
【操作】
正規化後的樣子如下 ⮕
【原則】
符合第一正規化。
消除部分功能相依,每一個非 key 欄位必須完全相依主鍵
如下單者姓名 buyer 相依於下單者編號 buyer_code、店家名稱 store_name 相依於店家代碼 store_code。
【解法】
檢查是否存在「部分功能相依」(可從多個欄位組成的 pk 開始檢查)。
將「部分功能相依」的欄位分割出去,另外組成新的資料表。
【操作】
下單者姓名與下單者編號 ⮕ 另建 buyer 表
店家名稱與店家代碼 ⮕ 另建 store 表
同時我們可以看出,只要給定下單者編號、店家代碼就可以得出唯一一組商品訂購資訊,所以 pk 是 (下單者編號, 店家代碼) 的組合。
正規化後,訂購紀錄的樣子 ⮕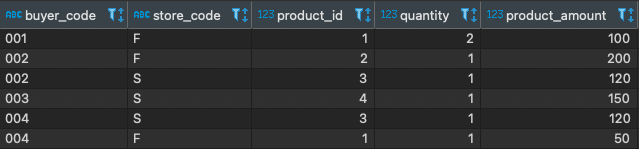
【原則】
符合第二正規化。
各欄位之間沒有存在遞移相依的關係(與 pk 無關的相依性)。商品編號 product_id 相依於 pk,而商品售價 product_amount 又相依於 product_id,因此 product_amount 與 pk 是遞移相依。
【解法】
檢查是否存在「遞移相依」的欄位。
將「遞移相依」的欄位分割出去,另外組成新的資料表。
【操作】
商品編號、商品名稱與商品售價 ⮕ 另建 product 表
正規化後,訂購紀錄的樣子 ⮕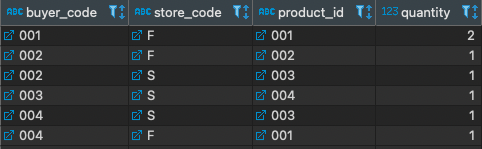
只需要 (下單者編號, 店家代碼, 商品編號) 的組合,就可以得到訂購數量。如此一來,要更新訂購數量時就方便許多!
資料表之間的關係變成 ⮕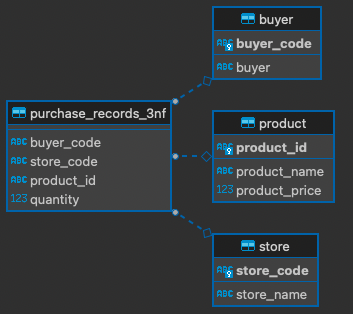
實務上,通常會進行到第三正規化。如果資料設計不夠完善(也就是未正規化),可能會導致操作上出現問題,例如:
透過適當的正規化,可以有效避免這些問題,並確保資料一致性。
營運了一段時間,公司提供的網購服務越來越受歡迎,累積的資料量也很可觀。公司高層秉持著「資料海裡淘金」的期待,找來一位資料分析師,希望定時針對用戶在各店家購買的金額與數量進行探索,結果分析師下了一個這樣的查詢指令 (query):
SELECT
r.buyer_code,
b.buyer,
r.store_code,
s.store_name,
SUM(r.quantity) AS total_quantity,
SUM(p.product_price) AS total_amount
FROM
purchase_records AS r
LEFT JOIN
buyer AS b
ON
r.buyer_code = b.buyer_code
LEFT JOIN
store AS s
ON
r.store_code = s.store_code
LEFT JOIN
product AS p
ON
r.product_id = p.product_id
GROUP BY
r.buyer_code,
b.buyer,
r.store_code,
s.store_name
ORDER BY
SUM(p.product_price) DESC,
SUM(r.quantity) DESC
這個 query 看似平凡,只是把後端工程師設計資料庫時,由於正規化規範拆出來的小表們全部都用 JOIN 拼接回去。但隨著商品數達到十萬級、用戶數達到百萬級,訂單數達到千萬級時,由於這個 query 對資料庫的讀寫操作 (IO,Input/Output) 造成沈重的負擔,導致網購系統越來越卡。
『抱歉,先請你暫停這段分析好嗎?』後端工程師對資料分析師這麼說。
『… 那我的工作怎麼進行?』資料分析師無奈地回應。
『以不影響到業務運行為主 …』後端工程師也很無奈。
眼見業務運行成為資料運用瓶頸,公司團隊覺得要想辦法解決才行。好像應該找個同時懂程式設計和資料運用的人,成為後端工程師與資料分析師的橋樑。
這就是資料工程師的誕生起源,他把上述的資料定時 (可能是每天做一次) 搬到另外一個資料庫裡,同時把資料分析師做的 JOIN 在新的資料庫裡做完。雖然分析沒辦法獲得即時的資料,但再也不會因為做分析導致交易變慢而影響公司的營運了!
常見的幾個 反正規化(denormalization) 手法如下:
一言以蔽之,就是運用另外儲存空間換取查詢效率。
後端工程師正規化以求資料庫的讀寫效率平衡,資料工程師做反正規化讓讀取效率極大化。資料分析師作為資料系統的取用者 (consumer) 看似被動,但若能在系統設計前期參與,預先提出分析上的考量,或許就能讓資料庫設計更為兼容。

圖/正規化與反正規化比較。簡書廷製。
明天我們來談談後端工程師打造的資料庫和資料工程師另建的資料庫,具體上有什麼差異吧!

